机器学习之卷积神经网络 && 卷积神经网络在NLP中的应用

文章目录
[toc]
机器学习之卷积神经网络
标签(空格分隔): 机器学习 卷积神经网络
1. 神经网络是啥?
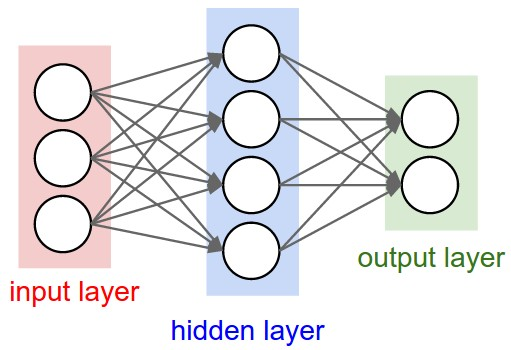
神经网络其实就是按照一定规则连接起来的多个神经元。上图展示了一个全连接(full connected, FC)神经网络,通过观察上面的图,我们可以发现它的规则包括:
- 神经元按照层来布局。最左边的层叫做输入层,负责接收输入数据;最右边的层叫输出层,我们可以从这层获取神经网络输出数据。输入层和输出层之间的层叫做隐藏层,因为它们对于外部来说是不可见的。
- 同一层的神经元之间没有连接。
- 第N层的每个神经元和第N-1层的所有神经元相连(这就是full connected的含义),第N-1层神经元的输出就是第N层神经元的输入。
- 每个连接都有一个权值。
上面这些规则定义了全连接神经网络的结构。事实上还存在很多其它结构的神经网络,比如卷积神经网络(CNN)、循环神经网络(RNN),他们都具有不同的连接规则。
但是一个神经网络的搭建,都需要满足三个条件。
- 输入和输出
- 权重(w)和阈值(b)
- 多层感知器的结构
2. 神经网络的训练
搭建一个神经网络,首先要画出它的网络结构,也就是上面那张图。
不考虑超参数(hyperparameter),其中,最困难的部分就是确定权重(w)和阈值(b)。目前为止,这两个值都是主观给出的,但现实中很难估计它们的值,必需有一种方法,可以找出答案。
这种方法就是试错法。其他参数都不变,w(或b)的微小变动,记作Δw(或Δb),然后观察输出有什么变化。不断重复这个过程,直至得到对应最精确输出的那组w和b,就是我们要的值。这个过程称为模型的训练。
因此,神经网络的运作过程如下。
- 确定输入和输出
- 找到一种或多种算法,可以从输入得到输出
- 找到一组已知答案的数据集,用来训练模型,估算w和b
- 一旦新的数据产生,输入模型,就可以得到结果,同时对w和b进行校正
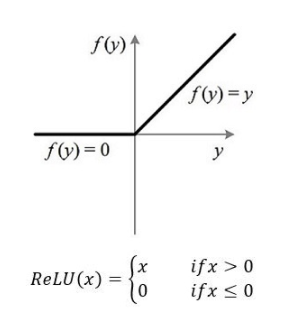
上述是阮一峰老师对神经网络运作过程的定义。 下面我以三层BP神经网络为例,简单介绍它的构造以及传播过程: 1. 确定隐藏层数目,输入输出层 2. 选择每一层对应的激活函数:为什么要引入激活函数呢?因为有些问题,线性模型不能很好的解决,所以我们需要对线性模型做一个变换,或者引入激活函数(activation function),常用的激活函数有tanh,sigmoid,ReLU,Softmax等。我们一般使用ReLU作为中间隐层神经元的激活函数,AlexNet中提出用ReLU来替代传统的激活函数是深度学习的一大进步。 3. 确定损失函数(loss function) 4. 选择合适的方法更新参数(这里以梯度下降法为例),确定学习率$$ \alpha $$,学习率决定学习快慢。但是设置过大可能会导致函数不收敛。 5. 随机初始化参数(w) (b)将数据喂入神经网络。 6. 根据下图公式进行前向传播 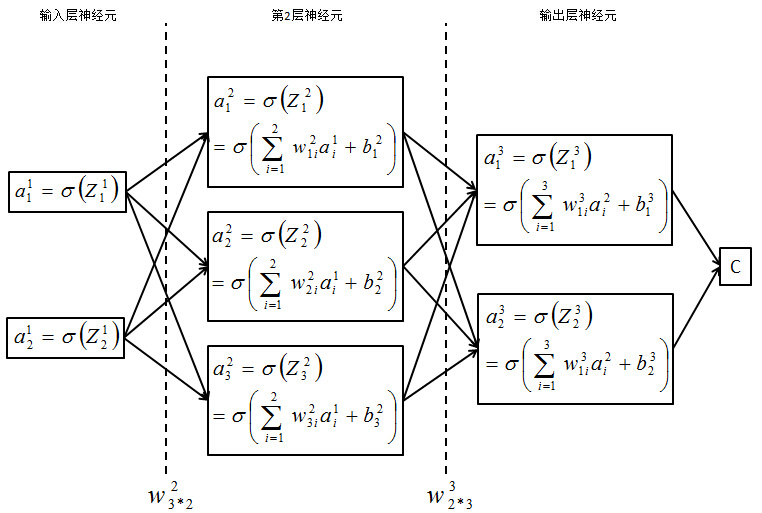 7. 如下图所示C在这里是代价函数,这是一个求最小化损失函数问题。首先来看看梯度下降的一个直观的解释。比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置的时候,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
7. 如下图所示C在这里是代价函数,这是一个求最小化损失函数问题。首先来看看梯度下降的一个直观的解释。比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置的时候,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。 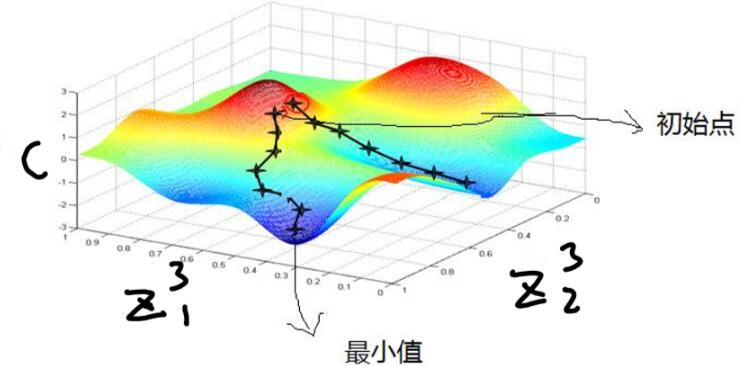 反向传播第一步,求C对最后一层中的两个分量求偏导。
反向传播第一步,求C对最后一层中的两个分量求偏导。 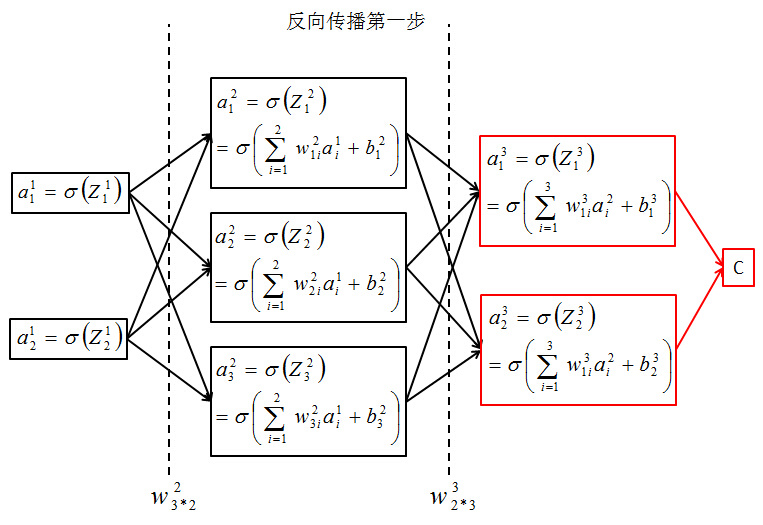 反向传播第二部,求C对第二层中的三个分量求偏导。
反向传播第二部,求C对第二层中的三个分量求偏导。 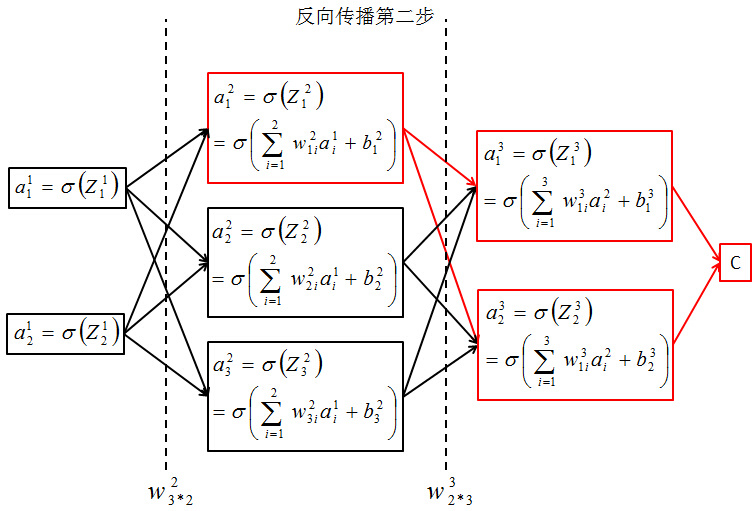 都用到了积分的链式求导法则。总之,选定损失函数与激活函数,这些问题都可以迎刃而解。 8. 参数更新,重复前向传播,反向传播过程,直到损失函数小于某个设定好的数。 现在大家对神经网络应该有了基本的了解,现在我们来看看卷积神经网络(CNN)
都用到了积分的链式求导法则。总之,选定损失函数与激活函数,这些问题都可以迎刃而解。 8. 参数更新,重复前向传播,反向传播过程,直到损失函数小于某个设定好的数。 现在大家对神经网络应该有了基本的了解,现在我们来看看卷积神经网络(CNN)
3. 卷积神经网络处理(CNN)来处理中文文本。
3.1 什么是卷积神经网络(CNN)?
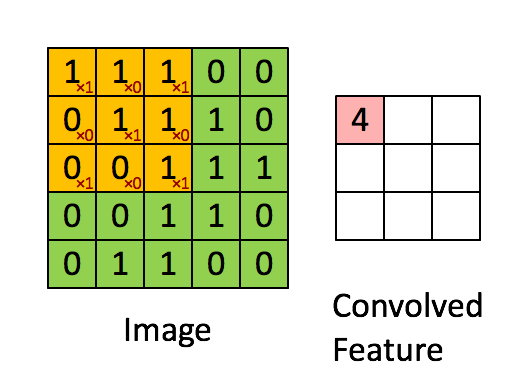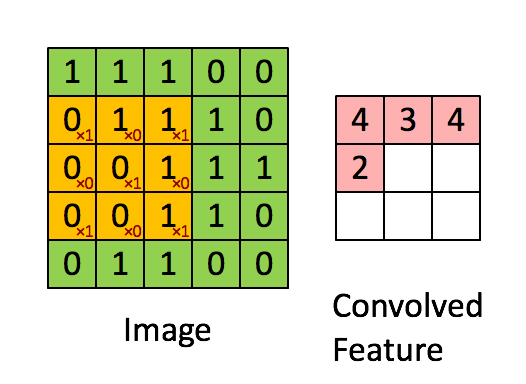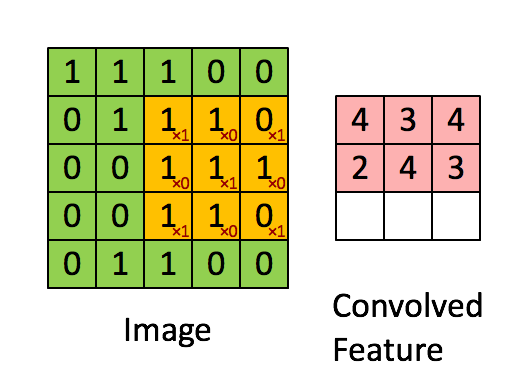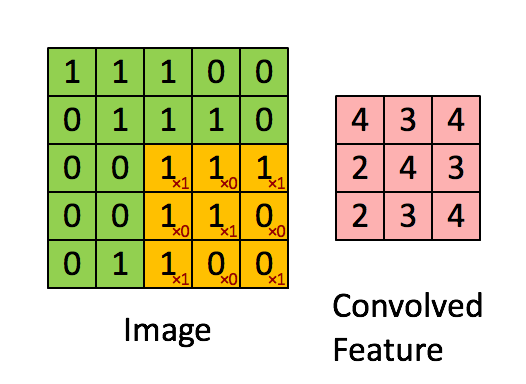 上图是3x3的滤波器做卷积运算的直观显示。 把左侧的矩阵想象成一幅黑白图像。每一个元素对应一个像素点,0表示黑点,1表示白点(灰度图的像素值一般是0~255)。移动窗口又称作核、滤波器或是特征检测器。这里我们使用3x3的滤波器,将滤波器与矩阵对应的部分逐元素相乘,然后求和。我们平移窗口,使其扫过矩阵的所有像素,对整幅图像做卷积运算。
上图是3x3的滤波器做卷积运算的直观显示。 把左侧的矩阵想象成一幅黑白图像。每一个元素对应一个像素点,0表示黑点,1表示白点(灰度图的像素值一般是0~255)。移动窗口又称作核、滤波器或是特征检测器。这里我们使用3x3的滤波器,将滤波器与矩阵对应的部分逐元素相乘,然后求和。我们平移窗口,使其扫过矩阵的所有像素,对整幅图像做卷积运算。
说到CNN,大家自然想到图像处理。 说到NLP,大家自然想到LSTM,RNN。 但是,16年的斯坦福论文表明,CNN照样可以应用于NLP,并且效果可能更好。 我用清华大学数据集做了训练,结果标明RNN和CNN在测试集都可以达到90%左右的效果,但是,CNN比RNN快了很多倍。
卷积神经网络与普通神经网络的区别在于,卷积神经网络包含了一个由卷积层和子采样层构成的特征抽取器。在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接。在CNN的一个卷积层中,通常包含若干个特征平面(featureMap),每个特征平面由一些矩形排列的的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。子采样可以看作一种特殊的卷积过程。卷积和子采样大大简化了模型复杂度,减少了模型的参数。
3.2 如何将CNN用于NLP呢?
3.2.1 NLP的输入问题
NLP任务的输入不再是像素点了,大多数情况下是以矩阵表示的句子或者文档。矩阵的每一行对应于一个分词元素,一般是一个单词,也可以是一个字符。也就是说每一行是表示一个单词的向量。通常,这些向量都是word embeddings(一种底维度表示)的形式,如word2vec和GloVe,但是也可以用one-hot向量的形式,也即根据词在词表中的索引。若是用100维的词向量表示一句10个单词的句子,我们将得到一个10x100维的矩阵作为输入。这个矩阵相当于是一幅“图像”。
3.2.2 如何解决不同的文本长度不统一的问题?
这是一个非常显然的问题,在LeNet-5中,每个输入都是32*32的图像文件,这样我们才能设置固定大小和数量的filters,如果图像分辨率发生了变化,那么就会造成多余的conv操作的结果丢失,从而对模型的结果产生影响,或者会使得网络内部状态发生混乱。在图像处理中,可以通过固定输入的图像的分辨率来解决,但是在自然语言处理中,由于输入的是文档或者sentence,而输入的长度是不固定的,那么如何解决这个问题呢?其实,在NLP中,研究人员一般都采用的是“单层CNN结构”,这里的单层并不是只有一层,而是只有一对卷积层和池化层。可以看到,每次在卷积的时候,都是整行整行的进行的。
以下内容引用自Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings, 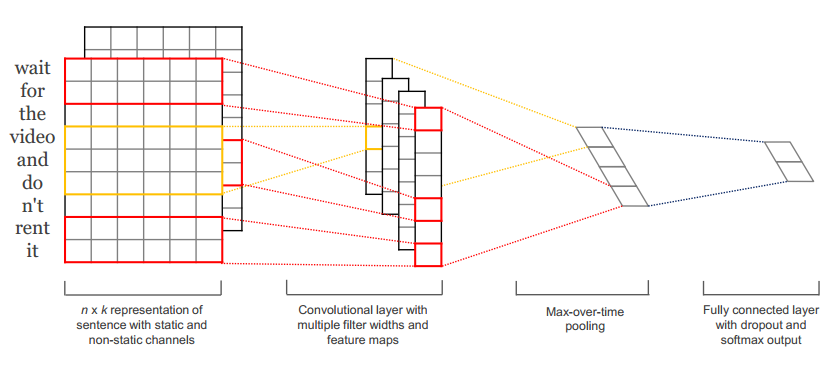 在不同的分类数据集上评估CNN模型,主要是基于语义分析和话题分类任务。CNN模型在各个数据集上的表现非常出色,甚至有个别刷新了目前最好的结果。令人惊讶的是,这篇文章采用的网络结构非常简单,但效果相当棒。输入层是一个表示句子的矩阵,每一行是word2vec词向量。接着是由若干个滤波器组成的卷积层,然后是最大池化层,最后是softmax分类器。该论文也尝试了两种不同形式的通道,分别是静态和动态词向量,其中一个通道在训练时动态调整而另一个不变。
在不同的分类数据集上评估CNN模型,主要是基于语义分析和话题分类任务。CNN模型在各个数据集上的表现非常出色,甚至有个别刷新了目前最好的结果。令人惊讶的是,这篇文章采用的网络结构非常简单,但效果相当棒。输入层是一个表示句子的矩阵,每一行是word2vec词向量。接着是由若干个滤波器组成的卷积层,然后是最大池化层,最后是softmax分类器。该论文也尝试了两种不同形式的通道,分别是静态和动态词向量,其中一个通道在训练时动态调整而另一个不变。 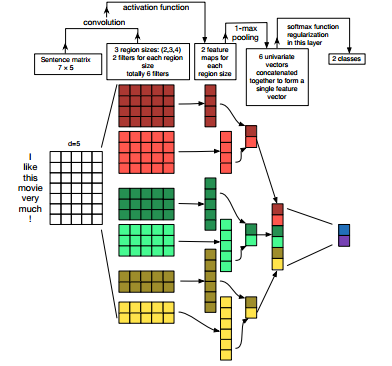 这里我们对滤波器设置了三种尺寸:2、3和4行,每种尺寸各有两种滤波器。每个滤波器对句子矩阵做卷积运算,得到(不同程度的)特征字典。然后对每个特征字典做最大值池化,也就是只记录每个特征字典的最大值。这样,就由六个字典生成了一串单变量特征向量(univariate feature vector),然后这六个特征拼接形成一个特征向量,传给网络的倒数第二层。最后的softmax层以这个特征向量作为输入,用其来对句子做分类;我们假设这里是二分类问题,因此得到两个可能的输出状态。
这里我们对滤波器设置了三种尺寸:2、3和4行,每种尺寸各有两种滤波器。每个滤波器对句子矩阵做卷积运算,得到(不同程度的)特征字典。然后对每个特征字典做最大值池化,也就是只记录每个特征字典的最大值。这样,就由六个字典生成了一串单变量特征向量(univariate feature vector),然后这六个特征拼接形成一个特征向量,传给网络的倒数第二层。最后的softmax层以这个特征向量作为输入,用其来对句子做分类;我们假设这里是二分类问题,因此得到两个可能的输出状态。
3.2.3 CNN的超参数问题
窄卷积 vs 宽卷积
在上文中解释卷积运算的时候,我忽略了如何使用滤波器的一个小细节。在矩阵的中部使用3x3的滤波器没有问题,在矩阵的边缘该怎么办呢?左上角的元素没有顶部和左侧相邻的元素,该如何滤波呢?解决的办法是采用补零法(zero-padding)。所有落在矩阵范围之外的元素值都默认为0。这样就可以对输入矩阵的每一个元素做滤波了,输出一个同样大小或是更大的矩阵。补零法又被称为是宽卷积,不使用补零的方法则被称为窄卷积。
步长
卷积运算的另一个超参数是步长,即每一次滤波器平移的距离。上面所有例子中的步长都是1,相邻两个滤波器有重叠。步长越大,则用到的滤波器越少,输出的值也越少。下图来自斯坦福的cs231课程网页,分别是步长为1和2的情况:  卷积步长。左侧:步长为1,右侧:步长为2。
卷积步长。左侧:步长为1,右侧:步长为2。
池化层
卷积神经网络的一个重要概念就是池化层,一般是在卷积层之后。池化层对输入做降采样。常用的池化做法是对每个滤波器的输出求最大值。我们并不需要对整个矩阵都做池化,可以只对某个窗口区间做池化。例如,下图所示的是2x2窗口的最大值池化(在NLP里,我们通常对整个输出做池化,每个滤波器只有一个输出值): 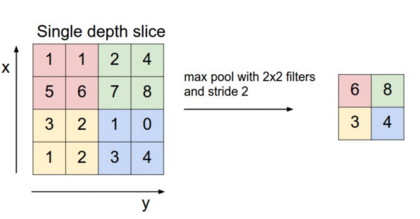 池化的特点之一就是它输出一个固定大小的矩阵,这对分类问题很有必要。例如,如果你用了1000个滤波器,并对每个输出使用最大池化,那么无论滤波器的尺寸是多大,也无论输入数据的维度如何变化,你都将得到一个1000维的输出。这让你可以应用不同长度的句子和不同大小的滤波器,但总是得到一个相同维度的输出结果,传入下一层的分类器。
池化的特点之一就是它输出一个固定大小的矩阵,这对分类问题很有必要。例如,如果你用了1000个滤波器,并对每个输出使用最大池化,那么无论滤波器的尺寸是多大,也无论输入数据的维度如何变化,你都将得到一个1000维的输出。这让你可以应用不同长度的句子和不同大小的滤波器,但总是得到一个相同维度的输出结果,传入下一层的分类器。
池化还能降低输出结果的维度,(理想情况下)却能保留显著的特征。你可以认为每个滤波器都是检测一种特定的特征,例如,检测句子是否包含诸如“not amazing”等否定意思。如果这个短语在句子中的某个位置出现,那么对应位置的滤波器的输出值将会非常大,而在其它位置的输出值非常小。通过采用取最大值的方式,能将某个特征是否出现在句子中的信息保留下来,但是无法确定它究竟在句子的哪个位置出现。这个信息出现的位置真的很重要吗?确实是的,它有点类似于一组n-grams模型的行为。尽管丢失了关于位置的全局信息(在句子中的大致位置),但是滤波器捕捉到的局部信息却被保留下来了,比如“not amazing”和“amazing not”的意思就大相径庭。
在图像识别领域,池化还能提供平移和旋转不变性。若对某个区域做了池化,即使图像平移/旋转几个像素,得到的输出值也基本一样,因为每次最大值运算得到的结果总是一样的。
通道
通道即是输入数据的不同“视角”。比如说,做图像识别时一般会用到RGB通道(红绿蓝)。你可以对每个通道做卷积运算,赋予相同或不同的权值。你也同样可以把NLP想象成有许多个通道:把不同类的词向量表征(例如word2vec和GloVe)看做是独立的通道,或是把不同语言版本的同一句话看作是一个通道。
卷积神经网络(CNN)在自然语言处理的应用
1. 模型的构建
下图是本次项目中使用的卷积神经网络结构图: 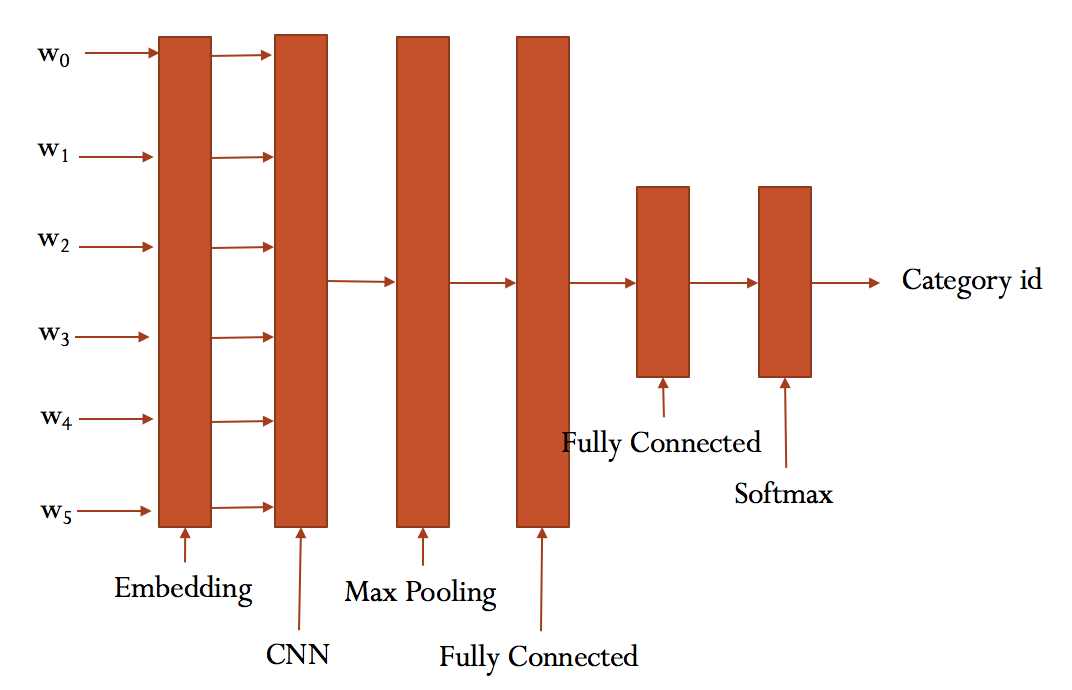
- 首先确定网络结构,如上图。
- 本项目第一个Fully Connected层之后接dropout以及relu激活函数。
 由于是多分类问题,所以输出层使用Softmax函数。
由于是多分类问题,所以输出层使用Softmax函数。 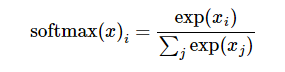
- 损失函数(loss function)用交叉熵(Cross Entropy)函数
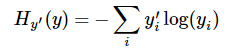
- 优化器用了AdamOptimizer 前面我们已经介绍了Embedding层,卷积层,池化层,现在我们来介绍全连接层(Fully Connected)全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用,传统的网络我们的输出都是分类,也就是几个类别的概率甚至就是一个数–类别号,那么全连接层就是高度提纯的特征了,方便交给最后的分类器或者回归。因为全连接的参数太多了,所以我们需要dropout一部分参数。
上述模型用以下代码来构建:
|
|
2. 数据预处理
网络构建好了,然后我们通过以下代码对THUCNews数据集进行处理,将数据集都保存到txt文件中。数据集划分为70%训练集 15%验证集 15%测试集,运用以下代码对数据进行预处理。
|
|
我们的数据集划分如下 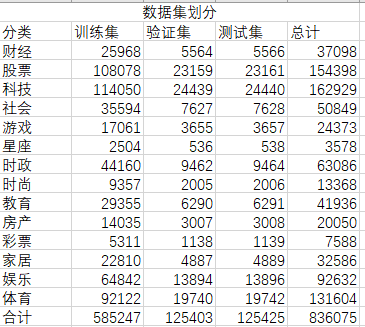 经过预处理,得到以下格式的数据。
经过预处理,得到以下格式的数据。
| Data | Shape | Data | Shape |
|---|---|---|---|
| x_train | [585247, 600] | y_train | [585247, 14] |
| x_val | [125403, 600] | y_val | [125403, 14] |
| x_test | [125425, 600] | y_test | [125425, 14] |
3. 模型的训练
现在开始将数据喂进输入层,进行传播。也是两步前向传播和反向传播。
前向传播:输入数据->通过embedding层将输入的一维序列转为2维矩阵,比如输入层有m个句子,经过embedding层处理之后得到的是一个[m,600,64]的矩阵。然后就可以进行卷积,池化等操作了。 反向传播:确定了每个层的激活函数,以及损失函数,选择了AdamOptimizer优化方法。利用TensorFlow即可自动完成一系列运算。
由于数据量巨大,我们使用了阿里云的竞价服务器来跑这个神经网络,
CNN训练过程如下
|
|
可以看出在验证集上的最佳效果为85.23%。
4. 模型的检验
开始跑测试集,
|
|
在测试集上的准确率达到了92.24%,根据查准率与查全率(Precision & Recall)的调和平均值F1-Score来看,最低为财经类的0.80,其它的几乎都在0.90左右,是一个很不错的成绩。